I will also enumerate all the other not-so-popular sorting algorithms at the end as appendix.
1. Selection Sort:
Selection sort is the simplest and the most straight forward sorting algorithm. Selection sort iterate through the elements to look for the smallest at first(select the smallest element), put it in the right place, and then select the second smallest element and put it in the sorted place, and so on. It runs O(n^2).
Implementation:
2. Insertion Sort:Implementation:
Insertion sort is the first sorting algorithm that mentioned in CLRS book. It is also the first algorithm that analyzed in detail in the textbook. It interpret insertion sort as sorting piles of card that faced down on the desk, our right hand pick the cards one by one from desk to insert to our left hand in order. What we essentially doing in this insertion sorting process is we go through all the card already in the left hand, compare them with the one at right hand, insert this right handed card into cards at left hand.
Following the basic ideas above about insertion sort. We come up the implementation as in-place implementation, which reorganize the element in memory right upon the initial array. What we do is we iterate through the elements starting from the second element, comparing it with elements before it, we should be able to find the right position this element should belong to. we shift all the elements between the correct position(included) and its original position(excluded) to right, leave the correct position for the element and move the element to it.
The following diagram shows how Insertion Sort work:

The pseudo code from CLRS is: (Pay attention to the while loop)


The implementation of Insertion Sort is:
Merge sort is used to describe the divide and conquer methodology. The basic ingredient of Merge Sort is MERGE() method. What MERGE() does is it take two array, both of which is sorted, merge them to form single array, which is also sorted. The idea of merge sort is take a given array, recursively dividing and merging the sub-arrays using MERGE() method.
The MERGE() method pseudo code from CRLS:

The MERGE-SORT() pseudo code from CRLS:

The implementation of Merge sort:
4 Heap Sort:The MERGE() method pseudo code from CRLS:
The MERGE-SORT() pseudo code from CRLS:
The implementation of Merge sort:
In introducing the heap sort, the CRLS book introduce the heap concepts. Which basically a binary tree, with parents keys always greater or equal to children. One example heap to illustrate heap property is the following figure.

Heap usually represented by array. In this implementation, giving the index i of the array we can calculate the parents index by PARENT(i) return [i/2] (floor of the i/2), the left children index by LEFT(i) return 2i, and the right children RIGHT(i) return 2i+1.
To implement Heap Sort, We first need a method to MAX-HEAPIFY to maintain the max-heap properties. Another method BUILD-MAX-HEAP use MAX-HEAPIFY to build a max-heap from the given nodes. HEAPSORT() calls MAX-HEAPIFY and BUILD-MAX_HEAP to sorting in O(nlgn). The idea of HEAPSORT is exchange the root(maximum) with the last element in the heap, reduce the heap size by removing the largest element. Doing this iteratively will do the job of heap sort.
Following is the methods mentioned above and one figure to illustrate how heap sort work.






Here is the heap sort implementation:
Problems:
Here is the heap sort implementation:
Problems:
4.5 Priority Queues:
Priority Queues are normally implemented using heap. The max-priority queue is used in computer resource scheduling. The min-priority queue is used in event simulation, in which the events happened from small time value. The method max-priority queue normally support is:




Implementation:
Problems:
5. Quick Sort
Priority Queues are normally implemented using heap. The max-priority queue is used in computer resource scheduling. The min-priority queue is used in event simulation, in which the events happened from small time value. The method max-priority queue normally support is:
HEAP-MAXIMUM, //used for get the max
HEAP-EXTRACT-MAX, //used for get the max value and also remove it from the queue
HEAP-INCREASE-KEY, //used for modify the element in the queue if needed.
MAX-HEAP-INSERT, //used for insert element to the queue
Implementation:
Problems:
Quick Sort is the most interesting sorting algorithm reviewed so far. It performance is depends on partitioning and the analysis of it is nontrivial. I first present the idea of quick sort and some fundamental insight can come to most people's mind. Then I will discuss about it deep at the end of this post. The idea can really see as a evolution from merge sort. It use the idea of divid and conquer and recursion. Remember in merger sort, the MERGE() method used is suppose the merging subarrays are already sorted. Here quick sort have to do the sorting from scratch. The way it does it is to select a pivot element, when "divide"(divide in the divide and conquer), each of those subarray elements is compared to the pivot element and positioned correctly before they "merge". Think about it, if you can understand what said here, go back to the textbook for reference.
The Quick Sort pseudo code:


The Figure the illustrate how Quick Sort work:
 When writing quicksort code, keep this figure in your mind and the loop invariant during the initialization, maintenance, and termination: the element from p and i is always less than the pivot, the element from i+1 to j is always greater than the pivot r. Don't forget the i is initialized to p-1, which indicate the initially, the number of element in the smaller subarray, which is less then pivot, is 0;
When writing quicksort code, keep this figure in your mind and the loop invariant during the initialization, maintenance, and termination: the element from p and i is always less than the pivot, the element from i+1 to j is always greater than the pivot r. Don't forget the i is initialized to p-1, which indicate the initially, the number of element in the smaller subarray, which is less then pivot, is 0;
The implementation of Quick Sort:
The Quick Sort pseudo code:
The Figure the illustrate how Quick Sort work:
The implementation of Quick Sort:
Analysis of Quick Sort
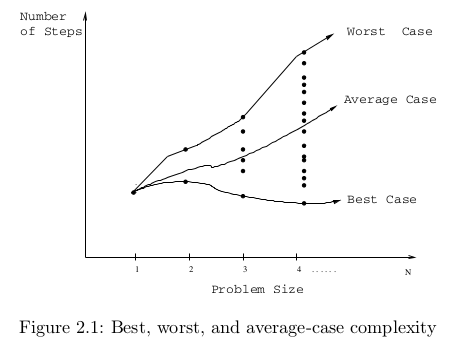
We want to take a look at the worst-case performance, best-case performance, and average case performance(expected running time).
Worst-case performance
If the partitioning routine produce one subproblem with n-1 and one with 0 elements. Assume this situation is happening in each recursive call. The recursive call take theta(n). So the running time is

Best-case performance
When the size of each of the subproblems not more than n/2. In this case, quick sort is much faster, the recurrence for the running time is then

Average-case performane
It more close to the best-case then the worst-case. The insight is really hide in the reflection of partitioning in the recurrence that describe the running time. Assume it alway produce a 9-to-1 proportional split, which seems quite unbalanced and prone to be believed quite close to the worst performance. In fact this is a wrong intuition. We obtain the recurrence


A Randomized version of Quicksort
The idea is to randomly select one element from the array, swap with the last element. Then do the partition. The RANDOMIZED-QUICKSORT() is based on this new partitioning metod.
The expected running time analysis in the book assume in each level of recursion, the split induced by RANDOMIZED-QUICKSORT() puts any constant fraction of the elements on one side of the partition, then the recursion tree has depth Theta(lgn), and O(n) work is performed at each level, which is the running time of partition method.
Tail-Recursive version of Quicksort and Stack Depth
ToDO: Sovling the problem 7.4 in the text book of CLRS.
Analysis of running time and comparisons
Implementation of quicksort: write a linked list version and a array version.
Problems:
1. What is the running time of QUICKSORT when all elements of array A have the same value?
2. What is the running time of QUICKSORT when all elements of array A have already sorted?
3. What is the running time of QUICKSORT when all elements of array A is sorted in decreasing order?
Answer: O(n^2). Because the comparison to the pivot is inclusive, "<=" in the pseudo code of quicksort. So the partition will be the worst case partition: 0 to n-1. No matter the elements is sorted in increasing order or decreasing order, the partition will always be the worst case partition. which results in a quadratic running time. In other words, if the partition is 0 to n-1, the recursive tree will have a linear height, in each height (each call to PARTITION()), it is n running time, so results to O(n^2) running time for all three cases. You can understand in this way: In particular, PARTITION, given a subarray A[p..r] of distinct elements in de-
creasing order, produces an empty partition in A[ p . . q − 1], puts the pivot (orig-
inally in A[r]) into A[p], and produces a partition A[p + 1..r] with only one
fewer element than A[p..r]. The recurrence for QUICKSORT becomes T(n) =
T (n − 1) + Theta(n), which has the solution T (n) = Theta(n2).